July 27 incident update


On Tuesday at 14:18 UTC several services provided by the Deno organization had a 6 minute service disruption. During this time projects hosted at Deno Deploy and deno.land website were not responding. We have concluded that this outage was the result a database migration becoming out of sync with various internal services in Deno Deploy. This post details what exactly happened, how we recovered the systems, and what we are doing to prevent this in the future.
All services are now operating normally again. No data was lost. We take outages like these seriously and sincerely apologize for the disruption.
Timeline of events
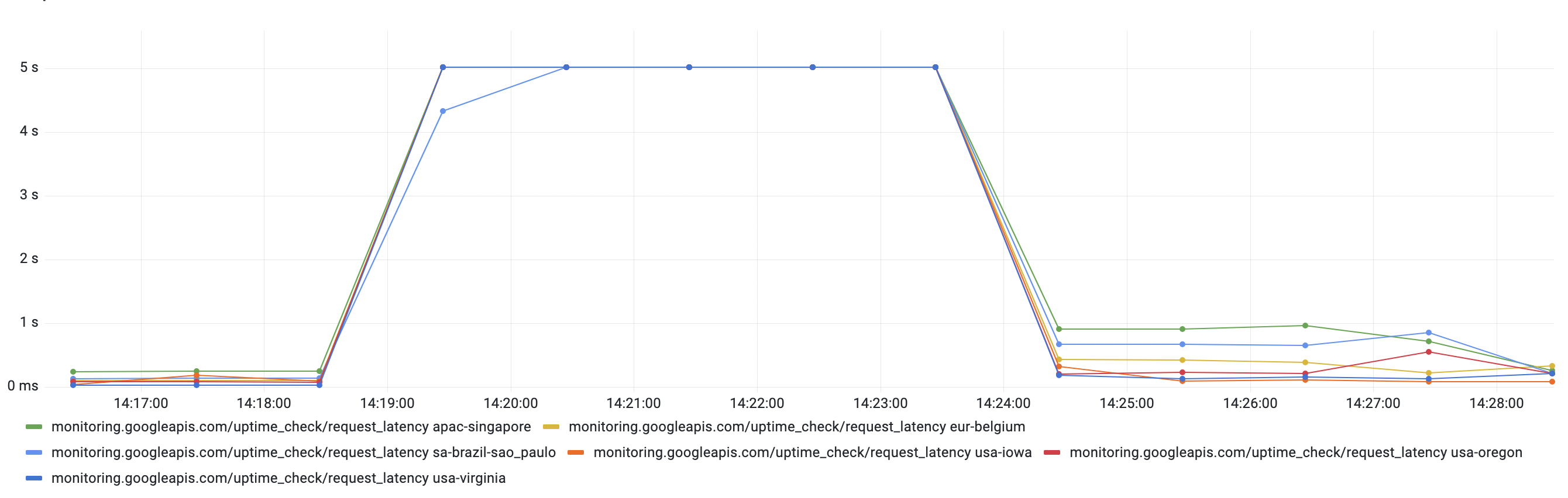
At 14:18 UTC a typical software deployment was initiated.
At 14:20 UTC an automated alarm triggered that a request to deno.land/std failed.
At 14:21 UTC we restored service to the deno.land website by redirecting traffic to our backup Cloudflare Workers. Other deployments running on Deno Deploy were still unreachable at this point.
At 14:24 UTC service was restored to Deno Deploy projects.
Root cause
The issue was caused by a change in our database schema, in which a column got dropped and replaced by another. A code change to make use of the new column was rolled out simultaneously.
Modifying the Deno Deploy infrastructure is not an atomic operation. While the update to the database was applied, a number of instances that were running code referencing the old column remained online. These instances periodically poll the modified table, but since an expected column had now gone missing, they started crashing.
As the update progressed over the course of the next few minutes, all instances running our old code got replaced, thus restoring the service.
Impact
During the 6 minute window, requests to Deno Deploy projects failed, including requests to deno.land/x and deno.land/std. Deno programs trying to download modules from /x or /std experienced failures.
What’s next?
This problem should have been caught when it was first rolled out to staging. We see there were failures in the staging logs that did not cause test failure or alarms. We have added new staging alerts that will catch such failures in the future.