
How we built a secure, performant, multi-tenant cloud platform to run untrusted code

We built Deno Deploy, our multi-tenant, globally distributed V8 isolate cloud, because we wanted to simplify hosting JavaScript (and TypeScript) in the cloud. While many users are using Deno Deploy to run their projects, there are also enterprises building on Deno Deploy’s infrastructure via Subhosting, which enable their users to easily write and run code in the cloud. With Subhosting, enterprises offer their users edge functions, host e-commerce storefronts close to users where every millisecond impacts conversions, and enable customization at the code level via “escape hatches” in low-code workflows. Our infrastructure is also battle tested — Netlify’s edge functions, powered by Deno Subhosting, processes over 255m requests per day.
While many companies are interested in securely running their users’ untrusted code, building a multi-tenant JavaScript platform that’s performant and secure while remaining affordable can be challenging. In this blog post, we’ll dive into the internals of Deno Deploy, share trade-offs between cost and performance, and the decisions we’ve made and why:
- Design requirements of a modern multi-tenant compute platform
- Lifecycle of a deployment
- Lifecycle of a request
- What’s next?
Design requirements of a modern serverless platform
A modern serverless platform should be simple (minimal config needed), performant, and secure. Those goals helped us determine these design requirements:
- highest level of security via maximum tenant isolation
- exceptional performance with minimum cold start times
- automatic global replication (user doesn’t need to do anything)
- effortless autoscaling (user doesn’t need to do anything)
- competitively priced and affordable
- fast global deployments, on the scale of seconds
With these constraints in mind, we designed the infrastructure architecture below to strike the right balance of performance and cost, while maximizing security.
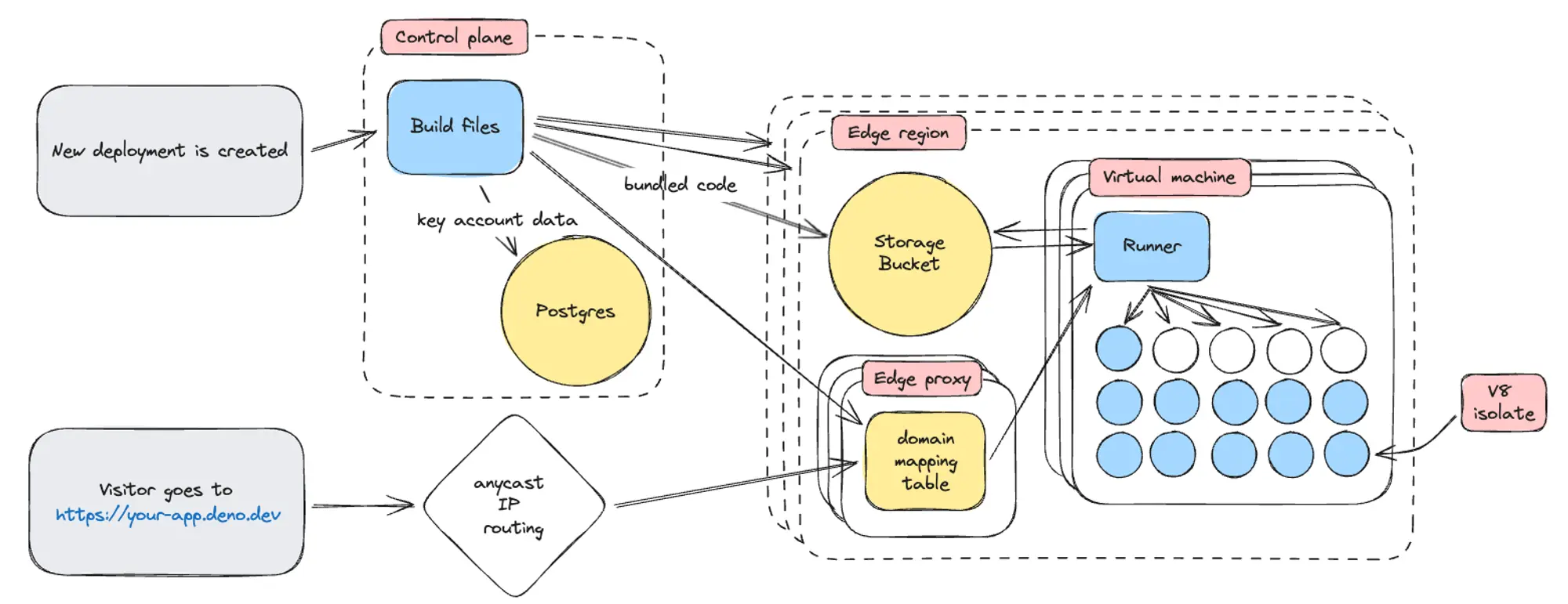
Deno Deploy is divided into two sections; in typical network engineering lingo we’ll call them the control plane and data plane.
In Deno Deploy, the control plane handles everything related to creating and managing deployments, user and organization accounts, analytics, metering and billing, and dashboards. The most pertinent part of the control plane for this blog post is its involvement in creating new deployments, which we’ll examine in the lifecycle of a deployment.
The data plane is where deployment code actually runs, and where HTTP requests destined for individual deployments are processed. This encompasses all the edge regions and everything they contain: storage buckets, edge proxies, and the virtual machines that run the V8 isolates (“runners”). We’ll go into more detail about how all of that works together when dive into the lifecycle of a request.
Lifecycle of a deployment
A user should be able to deploy globally and see those changes within seconds. This means our systems need to optimize for automatic global replication (which happens without any action from the user), as well as create a fast way to route traffic for new deployments.
User initiates a deployment
A user can trigger a deployment through merging to main on GitHub, via
deployctl , or through GitHub Actions workflow. While those facets are
important to the ease-of-use of Deno Deploy, we won’t go into the details of how
those systems work together. Let’s jump to when the deployment is initiated.
Pre-optimizing deployment code for V8
To best understand the pre-processing steps intended to minimize for cold starts when loading code into a V8 isolate and executing it, let’s first go over what actually happens when code is loaded into a V8 isolate.
To execute JavaScript, it’s first passed as an entrypoint file to V8. V8 looks for import statements, makes a list of dependencies, and asks for their code. Once it receives the code of its dependencies, it’ll scan for import statements, and ask for the code of those dependencies. This process of building out the entire program via breadth-first search can be time consuming, especially since V8 can not download all of the dependencies in parallel. If each remote fetch for a dependency takes 100ms, depending on how nested the dependencies are, the “network waterfall” could result in a very long wait time before all dependencies are loaded.
On top of that, since Deno natively supports TypeScript, there’s an additional transpile step that happens before sending the code to V8.
These steps add time to the cold start.
Fortunately, we can reduce cold start times and minimize latencies through pre-processing the deployment code. In this step:
- Using
swc, a Rust-based platform for working with TypeScript and JavaScript, the code is transpiled to JavaScript - We crawl through the import statements and download the entire code from its dependencies. Rinse and repeat until all dependencies are downloaded
- For npm dependencies, we remove any unnecessary code (such as tests, etc.) to reduce its footprint size
- The code is then ordered breadth-first search dependencies. The order matters because then we can stream the code to V8 for additional performance gains
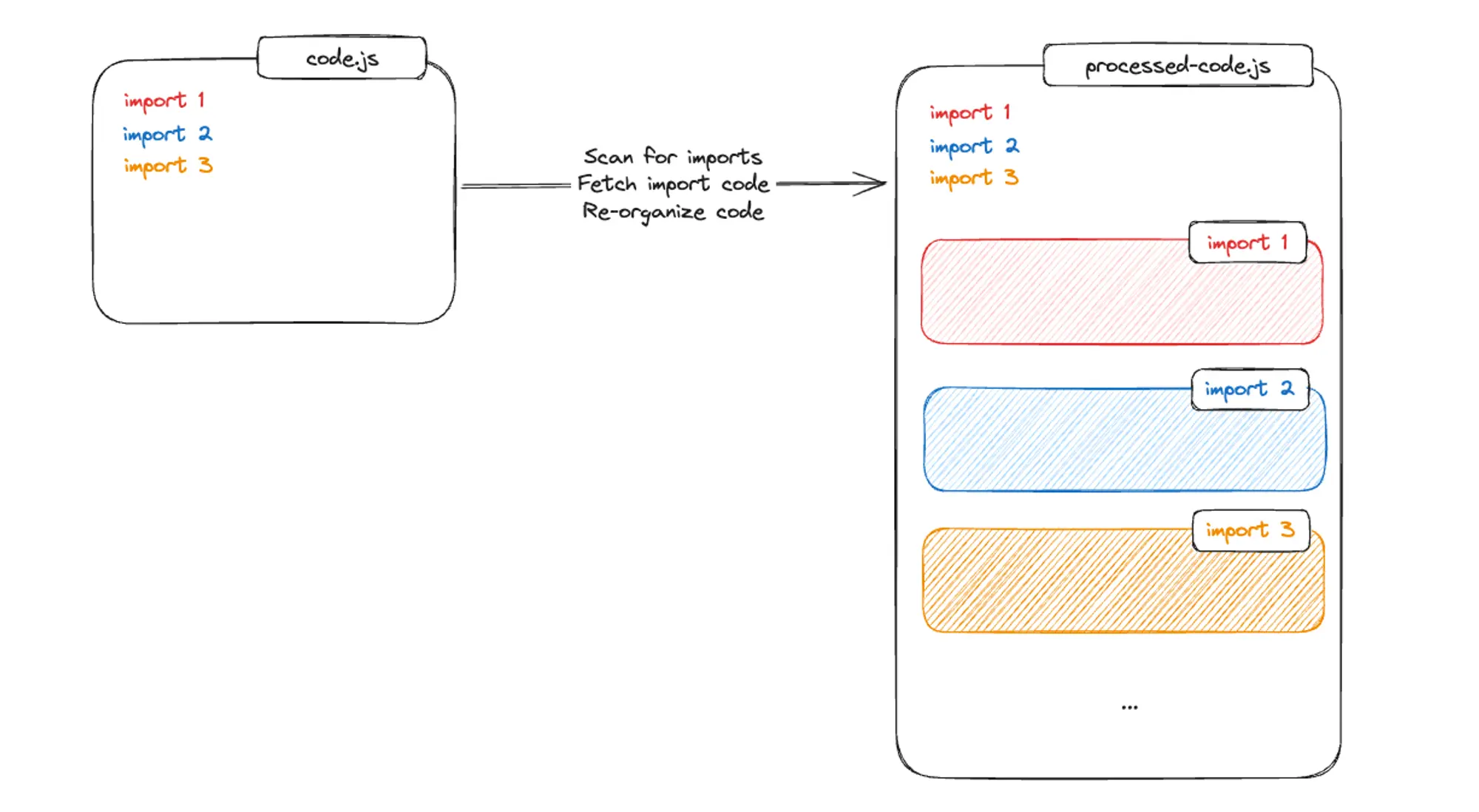
Another important reason we pre-process the code by downloading all dependencies is for the consistency and immutability of a deployment. Each time the deployment is executed, it should behave exactly the same way. For code importing unversioned dependencies or URL imports, it’s possible that those dependencies can change or the remote address no longer works. By pre-downloading and vendoring the dependencies with the deployment code, then saving it all together, we remove any risk of having the code behave differently on a subsequent execution.
Update data in Postgres
During this time, important information about the user’s project and deployment are updated in Postgres, which is our main database for managing user and project information.
It’s important to note that Postgres is not part of the critical path. As in, if Postgres is down, you might not be able to log into the Deno Deploy website, but existing deployments will still be available online. Keeping Postgres out of the critical path is an intentional choice to increase system reliability.
Replicate deployment code across edge regions in buckets
One of our core design requirements is that users deployments are automatically replicated globally without any additional config or action. This replication is necessary to minimize latencies by having fast cold starts everywhere on the globe. This means a copy of your source code must always be available in a nearby region.
The pre-processed code is uploaded to storage buckets around the world. Later, when the deployment is being accessed, we’ll load this code as-is into a V8 isolate.
Update domain mapping table
As the final step of the deployment process, the control plane sends a signal to the edge proxies in all edge regions to let them know how to update their domain mapping table.
This table is critical for routing incoming HTTP requests. The incoming request
contains a domain, which is used to look up its corresponding deployment_id on
a domain mapping table stored in memory. It’s important that this domain mapping
table is accurate so that every incoming request can be quickly routed to the
right place.
Once the edge proxy updates the domain mapping table in memory to include the new deployment and its domains, the deployment process is complete.
Lifecycle of a request
A deployment on Deno Deploy must be performant and secure, and can scale automatically. This means minimum cold starts, the deployment code is isolated and cannot access other deployments or the underlying systems, and the deployment scales automatically based on traffic without user configuration.
Let’s take a look at what happens when someone visits your deployment on Deno Deploy.
Route incoming request to closest region with Anycast
When the browser first sends a request to a deployment on Deno Deploy, it gets directed to the closest edge region via Anycast. Anycast is a routing approach where a single IP address is shared by servers in multiple locations. It’s commonly used in CDNs to bring content closer to end users.
Edge proxy routes to a V8 isolate
The incoming request has arrived at the edge region. But before we dive into how that is routed to the right V8 isolate to be executed, let’s quickly go over virtual machines and V8 isolates.
For many cloud hosting platforms, each customer would have their own virtual machine with the necessary binaries and files to run a web server. However, provisioning new virtual machines for scaling is slow. Alternatively, keeping them running at all times for a faster latencies, even when not handling traffic, can be expensive. This model did not support our design requirements of having fast deployments, minimum latencies, while being cost effective.
Instead, we built Deno Deploy using the same technology that powers the Deno runtime — the V8 isolate. These are instances of the V8 execution environment, similar to a JVM but for JavaScript. Because V8 isolates were designed to be used in the context of the web browser, where each open tab gets its own isolate, they’re designed to start very quickly and use relatively little memory.
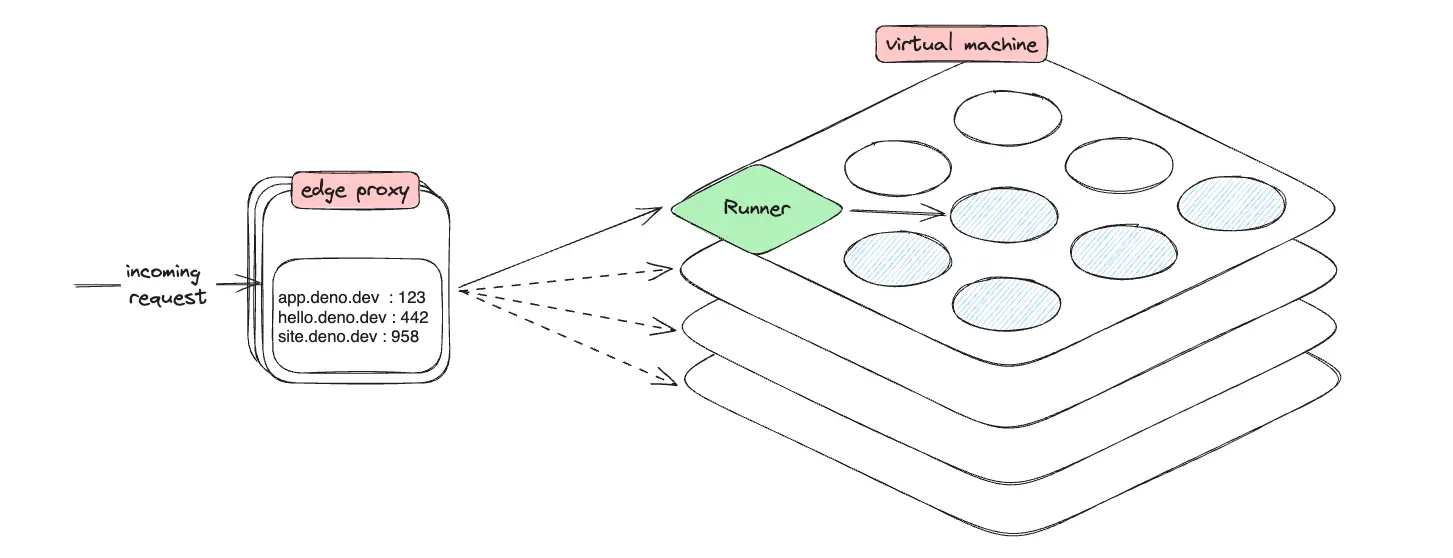
Deno Deploy creates “pools” of V8 isolates in a virtual machine, which we call a “runner”. Each runner manages the lifecycle of a large number of isolates, making sure that each piece of user code has an isolate available to them when they receive requests, and shutting them down again when they become idle. They also enforce that each isolate is well-behaved, and collect a bunch of statistics about how each piece of user code behaves so the edge proxy can make good scaling decisions.
All right, back to our edge proxy. When the edge proxy receives an incoming
request, it looks up the corresponding deployment_id from the
domain mapping table in memory, and decides
which runner should handle the request.
Overall, the edge proxy will aim to run an “appropriate” number of isolates per deployment, spread out across multiple runners. The “appropriate” number varies per deployment and over time, depending on how many requests per second the deployment receives and how many resources it takes to service one request.
When making the routing decision for individual requests, the edge proxy will first select a set of candidate runners based on what it thinks an appropriate number of isolates for the deployment. Subsequently, it will consider current CPU load on the runner as a whole, CPU use of the specific isolate inside that runner, and the isolate’s memory usage, to decide which runner can handle the request most quickly.
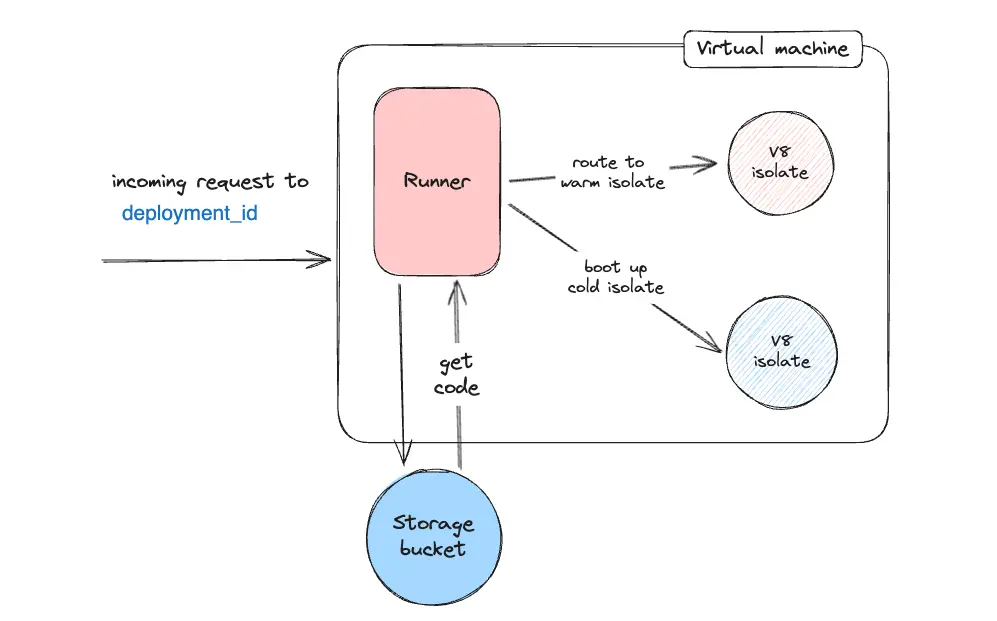
Once the runner receives the incoming request with a deployment_id, it checks
if there is already a V8 isolate running this deployment. If there is, it’ll
send the request to that V8 isolate directly. If not, it will pull
the pre-optimized deployment code from
the closest code storage bucket and load it into a fresh isolate.
Code is executed, securely
Since we allow anyone with a GitHub account to deploy and run code on our infrastructure, security is of utmost concern. Deployments that can access another deployment, or even the underlying infrastructure, are security violations that could lead to loss of confidence and customers in your platform.
That’s the tough part about building infrastructure to run third party untrusted code. Our friends at ValTown say it the best — “the default way to run untrusted code is dangerously.” In order to turn this into a business, security must be the most important consideration.
So when the request is received by the code in a V8 isolate, how do we make sure all security and isolation measures are taken?
We designed the system from the ground up to be secure. We started by coming up with a threat model and various scenarios in which a single bad actor can bring down the entire system or breach others’ deployments. We developed 5 directives, in which each deployment (a single tenant) must:
- Have access only to its own runtime (JavaScript objects, methods)
- Have access to its own data (file, code, databases, environment variables)
- Have no access to Deno Deploy internals, such as the underlying operating system and internal services
- Not deny resources (e.g. CPU, memory) to other isolates
- Not use Deno Deploy for unintended use cases (e.g. mining bitcoin)
From this, we used various technologies such as namespaces, cgroups, seccomp filters, and more to ensure multiple layers of security around the user’s tenant’s process. And, should malicious code somehow hack multiple layers to breach security, we’ve built other mechanisms, such as a “watch dog”, to monitor resources and terminate suspicious tenants.
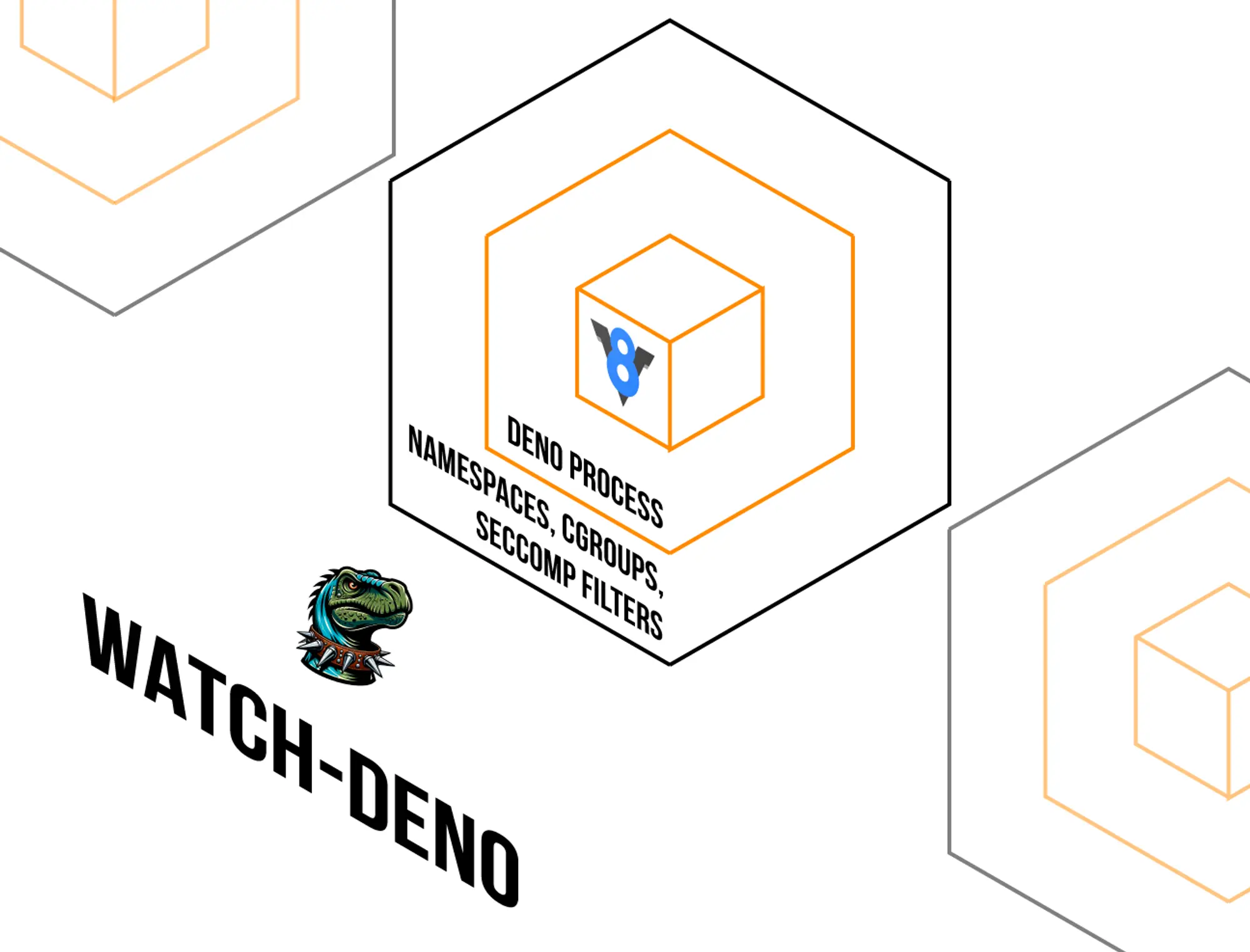
Security goes beyond our technologies, as well. To earn the trust of our users and enterprise customers, security is also an organizational concern, as we’re compliant with SOC 2 standard for security, availability, and confidentiality.
What’s next
Building a multi-tenant cloud platform that is simple to use with automatic scaling and replication, performant with minimal latencies and cold start times, all the while being cost competitive, can be tricky. However, we hope to have shed a bit of light on our approach towards building Deno Deploy and Deno Subhosting with this blog post.
If you’re interested in building a serverless deployment platform to securely run your users’ untrusted code with minimum cold start times, but do not want the headache of maintaining your own infrastructure, check out Deno Subhosting. It’s a REST API that allows you to programmatically manage projects, deployments, etc. without config or scaling from you or your users.
🚨️ Want to run users’ untrusted code securely without building it from scratch?
Check out Deno Subhosting, where you can run JavaScript from multiple users in a secure, hosted sandbox in minutes.