
The Future of the Web is on the Edge

In the beginning, there was a single computer on a desk in a basement in Switzerland. It had a red-inked label:

32 years later, there are hundreds of millions of versions of that computer all around the world. Some are even powered down by default.
But developing for the web still feels as if there is only one machine. We develop as if our code is going to be deployed on a single instance of a server somewhere in a huge data center in Virginia, California, or Switzerland.
But this doesn’t have to be the case anymore. For years, anything static was served from CDNs around the globe, close to users. Now, the same is starting to be true of dynamic web apps. You can deploy it all, everywhere.
What is the edge?
When people say “the edge,” they mean that your site or app is going to be hosted simultaneously on multiple servers around the globe, always close to a user. When someone requests your site/app, they will be directed to the one closest to them geographically. These distributed servers not only serve static assets, but can also execute custom code that can power a dynamic web app.
Moving servers closer to end-users is also a physical approach towards latency optimization. This means lower latency on every single page load. The longer your pages take to load, the more likely users will bounce. 32% more likely according to Google research when load speeds go from 1 second to 3 seconds. 90% more likely when speeds go from 1 second to 5 seconds. Users will visit 9 pages when pages load in 2 seconds, but only 3 pages when they load in 7 seconds.
That’s the gist. Now the nuance.
You’ve built an app. It’s cool. It does fun things. You want to show it to the
world, so you deploy it. For ease, you use Heroku. You git push heroku main
and then head to myfunapp.com to check out your handiwork.
By default, runtimes in Heroku are deployed in the AWS data center in northern Virginia. This is great, for some people. For example, if you live mere miles from the data farmlands of upstate Virginia. Pretty much any request you make would be speedy as heck. But not everyone is lucky enough to live in the vicinity of huge beige, windowless warehouses. As it turns out, some people live in nice places.
Let’s look at the Time To First Byte (TTFB—how quickly the server responds with the first byte of data) for an app hosted in Virginia for different locations around the world:
| Location | Heroku TTFB |
|---|---|
| Frankfurt | 339.95ms |
| Amsterdam | 382.62ms |
| London | 338.09ms |
| New York | 47.55ms |
| Dallas | 144.64ms |
| San Francisco | 302ms |
| Singapore | 944.14ms |
| Sydney | 889.85ms |
| Tokyo | 672.49ms |
| Bangalore | 984.39ms |
As they would say in Frankfurt, nicht so gut. Because every request has to travel from these locations to the eastern United States and back again, the further away a user is the longer they’re going to be waiting for their data.
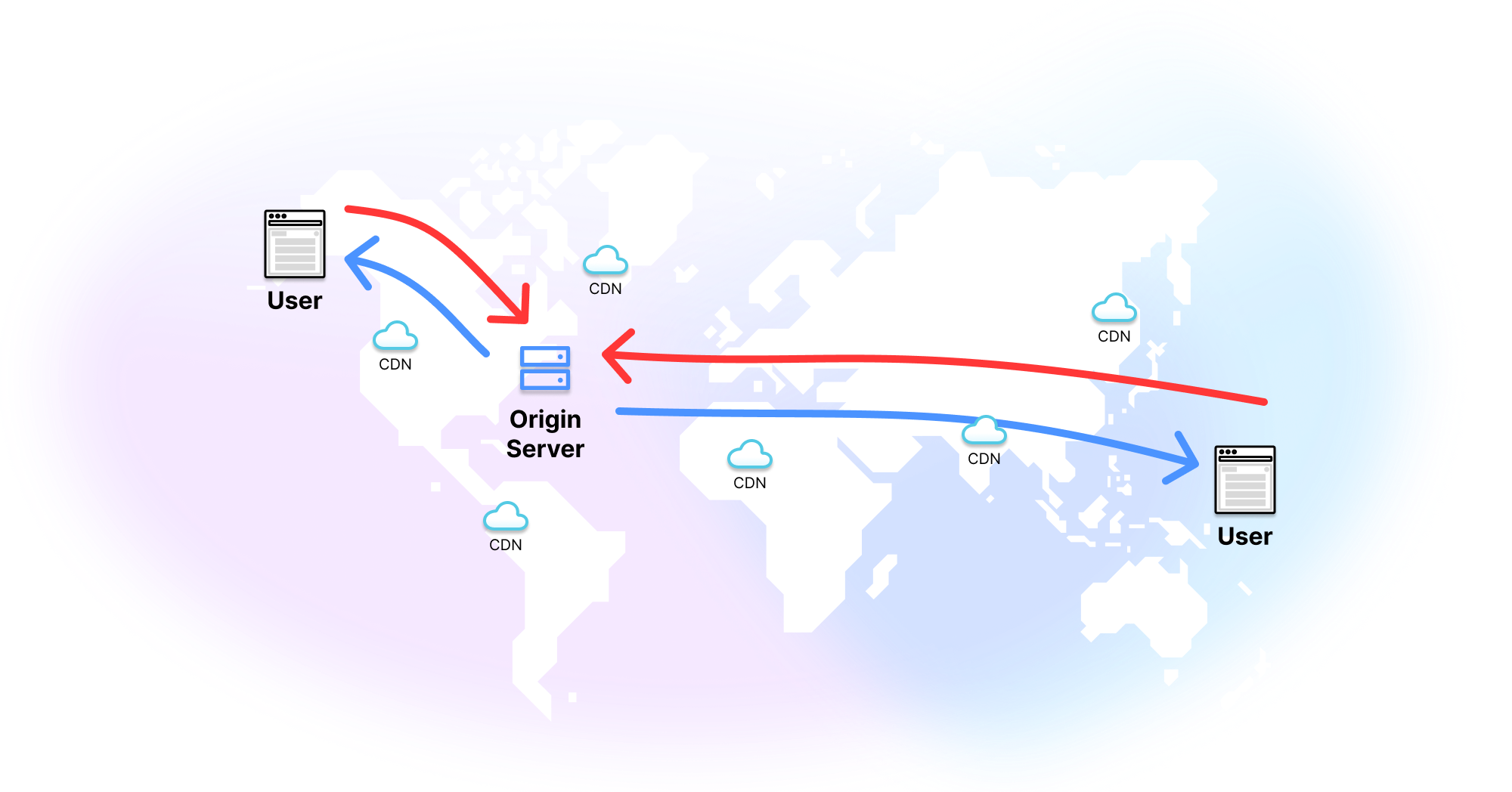
Once you get to the other side of the world, it’s taken almost one second to get even the first byte back from the server, let alone all the data for that single page. Add in all the pages on the site a user might want to visit, and you have a very bad experience for anyone in Bangalore or Sydney (or, tbh, anyone not in the eastern United States). You are losing pageviews, losing users, and losing money.
Let’s retry our speed check on deno.com, which is deployed on Deno Deploy, our edge network:
| Location | Heroku TTFB | Deno TTFB |
|---|---|---|
| Frankfurt | 339.95ms | 28.45ms |
| Amsterdam | 382.62ms | 29.72ms |
| London | 338.09ms | 22.3ms |
| New York | 47.55ms | 41.29ms |
| Dallas | 144.64ms | 29.28ms |
| San Francisco | 302ms | 44.24ms |
| Singapore | 944.14ms | 528.57ms |
| Sydney | 889.85ms | 26.46ms |
| Tokyo | 672.49ms | 19.04ms |
| Bangalore | 984.39ms | 98.23ms |
Except Singapore, we’ve got a world of sub-100 millisecond TTFBs. This is because instead of heading off to Virginia to get the site, each of these locations can use an edge server nearest to them. The edge is about getting 50ms response times vs 150ms response times. You can test this for yourself with a VPN. If you:
curl -I https://deno.landYou’ll get the server nearest your location:
server: deno/us-east4-aUsing a VPN to route my request through a proxy server, We can see a response from the nearest edge server to that location. Pretending we’re in Japan gives us:
server: deno/asia-northeast1-aPretending we’re in Ireland gives us:
server: deno/europe-west2-aAnd pretending we’re in Sydney, Australia gives us:
server: deno/australia-southeast1-bEach time the request is routed to the best option.
The centralized server model worked and continues to work for a lot of applications. But the scale of the web and the future of the web are fighting against this model. Let’s go through how this architecture came to be and how (and why) it’s changed over the years.

Servers as a concept were introduced in a 1969 RFC from the Network Working Group. That NeXT machine in Tim Berners-Lee’s office was the first web server, but the internet had already been rolling along for over 20 years by that point.

The ‘69 RFC laid out the foundation for how to transmit and receive data between a “server-host” and a user on ARPANET, the OG military-funded internet that initially connected four universities in the western US. The server was up and running by 1971 and a paper titled “A Server Host System on the ARPANET” published in 1977 by Robert Braden at UCLA (one of the connections on ARPANET) went into the details of that initial setup:
This paper describes the design of host software extensions which allow a large-scale machine running a widely-used operating system to provide service to the ARPANET. This software has enabled the host, an IBM 360/91 at UCLA, to provide production computing services to ARPANET users since 1971.
This is the first internet server: an IBM 360/91. The hardware and software have changed, and you no longer roll your own, but fundamentally this is still how the internet works today: servers providing a service.
Caching content close to users
This architecture has worked well for a long time. But by the late 90s and early 2000s, when the web started to become huge, cracks were starting to appear.
The first was what Akamai, when they launched the first Content Delivery Network (CDN) in 1998, called “hot spots.” Basically, servers crashing from too much traffic through popularity, or early DDoS attacks from 90s hackers.
Akamai’s CDN cached content in a distributed system of servers. A request was routed to the nearest of these servers. However, these are limited to static files: the HTML and CSS of your site, or images, videos, or other content on it. Anything dynamic still had to be handled by your core server.
CDNs continue to be a core piece of kit for the modern web. Most static files are cached somewhere. The first time you visit a website you might pull the HTML, CSS, or images straight from the origin server, but then they will be cached on a node close to you, so you (and others in your area of the network) will be served the cached content thereafter.
Less servers, more serverless
Servers also have problems in the opposite direction to overloading: under-utility. A server, like Tim Berners-Lee’s machine that cannot be “powered down”, has to be up 100% of the time. Even if your app gets one visit for ten seconds a day, you still pay for the other 86,390.
Serverless mitigates this problem. They can be spooled up and powered down at will. “Serverless” is a misnomer–a server is still involved. But you don’t have a dedicated server that is up all the time. Instead, the server is event-driven, only coming to life when a request is made.
Though there were earlier versions, AWS Lambda was the first serverless framework that saw widespread use.
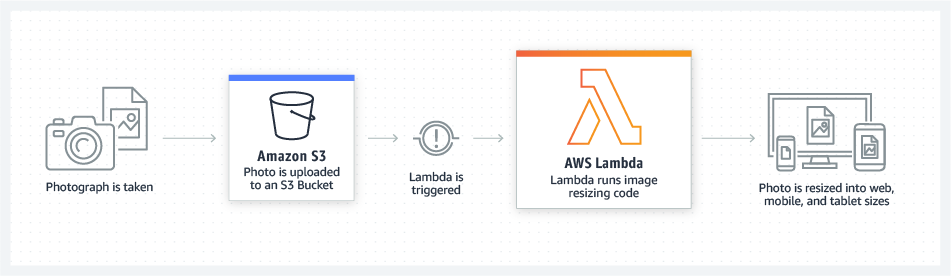
The benefits of serverless are two-fold:
- You only pay for what you use—just those 10 seconds if that’s all that’s happening on your app.
- You don’t have to worry about all the DevOps side of servers. No planning, no management, no maintenance.
The downsides mostly come with performance. You have a “cold start” problem with serverless functions, where the resources have to be provisioned each time, adding to latencies. And, the servers of serverless are still centralized, so you still have a long round-trip.
So we come to the present. Servers aren’t dying, but are far away and can fall over; CDNs cache your content close to users, but only the static stuff; and serverless means less DevOps and (potentially) lower costs, but higher latencies from cold starts.
Livin’ on the edge
The beauty of the edge is that it is taking the best part of CDNs (being close to users) and the best part of serverless (running functions) and marrying them together.

With the edge, you can execute custom code close to users. This has a ton of benefits.
Better performance
This is the only thing your users care about. Does your website load fast, does it hang, is it frustrating to use?
As a site or app is served from an edge server near them, it’s going to be faster than if on a centralized server.
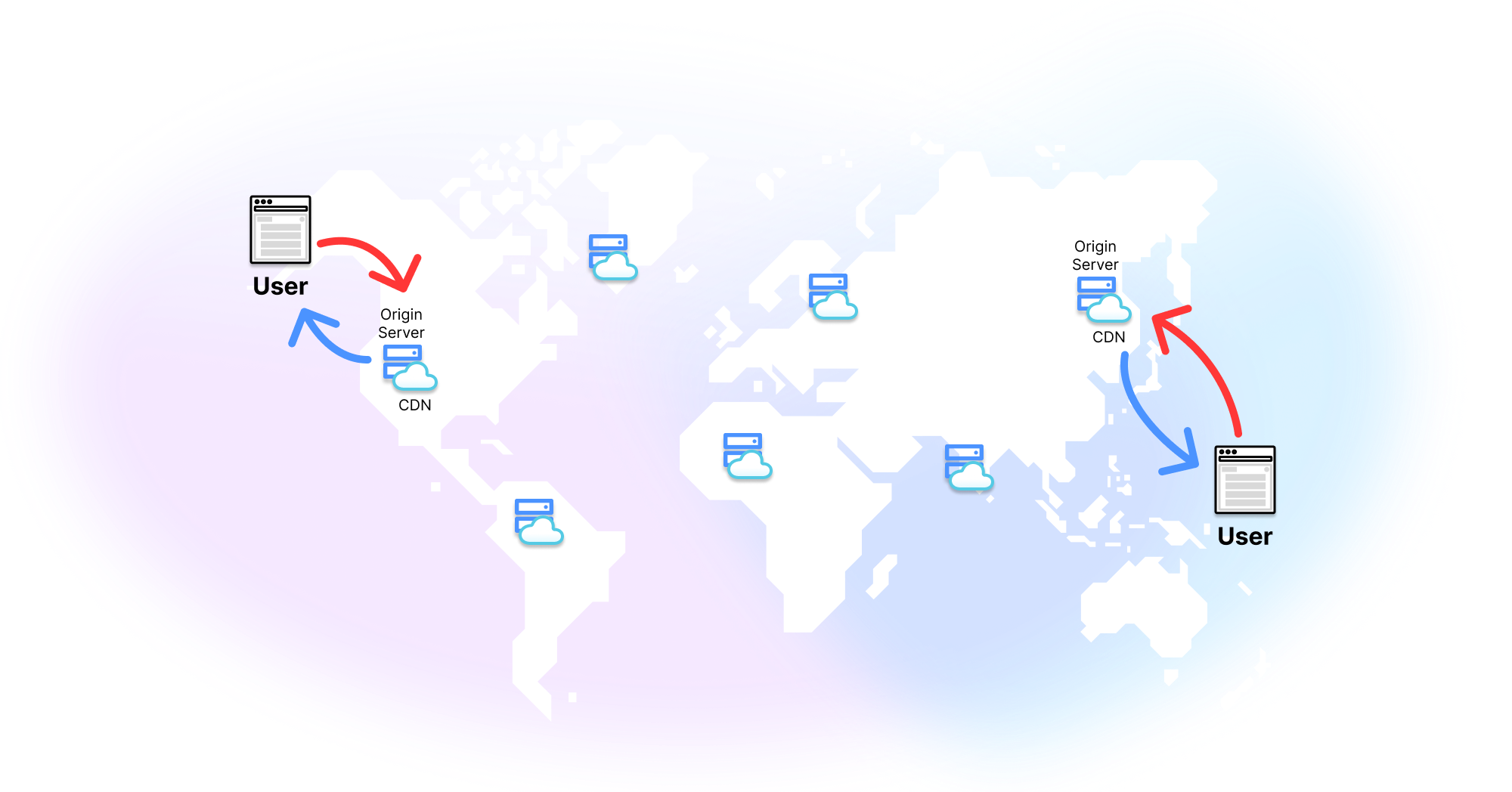
But the performance benefits don’t end there. As compute is performed on the edge, not by the user’s browser:
- The app is less resource-intensive on the end user’s machine, so less use of CPU and memory and less chance of browser hangs.
- Smaller payloads are sent to the end user, so less bandwidth is used.
- As functions are run in a controlled environment, there is consistent behavior of functions and APIs.
Better security
Moving computation from the client/device to the serverless edge also reduces potential vectors of attack on your app. In the words of Kitson Kelly, DX Engineering Lead at Deno, “that means you immediately decrease the amount of surface area that you expose to your end users.” He says (abbreviated for clarity):
Your device doesn’t have to make API calls to your backend services. I think all of us had to defend against that. But if you take the compute off the device and all you are sending is HTML and CSS, well, you’ve eliminated that problem. The only thing that gets off your network is the stuff you want to render to the customer.
In addition, DDoS attacks are more difficult. Any attacker isn’t taking down one server, they need to take down dozens, hundereds, maybe thousands across the globe. Even if they succeed in taking 10 servers offline, there might still be 20 available servers that traffic can be rerouted to.
Better developer experience
Right now, writing code for the edge is trickier than it needs to be. For the most part, this is due to the hybrid nature of edge development. Most frameworks that implement it aren’t edge-first, so developers must pick and choose whether any given function or page is server-side rendered on the edge or rendered in the browser.
This makes edge development more complex. But newer frameworks, such as Fresh, which delivers zero JavaScript to the client by default, simplifies optimizing for the edge by embracing server-side rendering and islands architecture. Developers using Fresh with our globally distributed JavaScript serverless edge network, Deno Deploy, can reap the benefits of edge and latency optimization, such as achieving a perfect Lighthouse score.
The edge is the next iteration of the internet. From the IBM 360/91 to Berners-Lee’s NeXT machine to Akamai’s CDNs to Amazon’s data farms to serverless to the edge. Each stage has built on the last, learning lessons and fixing mistakes. The edge is the next stage of making the web a faster, more secure place for users and developers.
Deploy to the edge globally in seconds with Fresh and Deno Deploy today.